

Von der Idee zur (Daten-)Plattform: Unsere modulare Open-Source Kubernetes-Architektur auf AWS
Wer Cloud-native Anwendungen betreiben möchte, merkt schnell: Ein Kubernetes-Cluster allein reicht nicht aus. Um Projekte zuverlässig, sicher und skalierbar zu betreiben, braucht es ein Zusammenspiel aus Infrastruktur, Automatisierung, Sicherheit, Monitoring und Nutzerverwaltung.
In den letzten Monaten haben wir eine modulare Deploymentplattform auf Basis von Amazon EKS aufgebaut. Ziel war es, neue Projekte schnell, konsistent und mit möglichst wenig manueller Arbeit an den Start bringen zu können – unser Fokus lag auf Daten- und KI-Anwendungen, die Plattform unterstützt aber jede Art von Anwendung, die containerisiert werden kann.
In diesem Beitrag zeigen wir, wie wir dabei vorgegangen sind, welche Open-Source-Werkzeuge wir nutzen und welche Architektur sich für uns bewährt hat.
Inhaltsverzeichnis
- Warum Open Source?
- Ziel: Eine wiederverwendbare, modulare Plattform
- Unsere Architektur im Überblick
- Typische Anwendungsfälle
- Lessons Learned
- Fazit: Offen, flexibel, zukunftssicher
Das Wichtigste im Überblick
- Eine Kubernetes-Infrastruktur allein reicht nicht – nötig ist ein integriertes Plattformkonzept mit Automatisierung, Sicherheit und Monitoring.
- Auf Basis von Amazon EKS wurde eine modulare, wiederverwendbare Plattform für skalierbares Deployment containerisierter Anwendungen entwickelt.
- Infrastruktur, Deployments und Workflows werden automatisiert über Terraform, Terragrunt, Argo CD und Argo Workflows gesteuert.
- Zentrale Verwaltung von Identitäten, Secrets und Images erfolgt über Keycloak, Vault und Harbor – mit klarer Trennung pro Projekt.
- Monitoring mit Prometheus und Grafana ermöglicht frühzeitiges Erkennen von Problemen und fundierte Kapazitätsplanung.
- Der konsequente Einsatz von Open-Source-Komponenten vermeidet Vendor-Lock-in und bietet volle Transparenz sowie Anpassbarkeit.
- Die Plattform reduziert Betriebsaufwand, steigert die Konsistenz neuer Projekte und ist für datengetriebene und KI-basierte Workflows optimiert.
Warum Open Source?
Für uns war Open Source nicht nur eine Kostenfrage, sondern eine bewusste Entscheidung. Wir wollten volle Transparenz darüber, wie unsere Werkzeuge funktionieren – mit der Möglichkeit, sie bei Bedarf selbst anzupassen. Gleichzeitig war es uns wichtig, nicht in eine Abhängigkeit von einzelnen Anbietern zu geraten (Vendor-Lock-in). Mit Open Source bleiben wir flexibel, auch wenn sich Anforderungen oder Technologien ändern. Zudem profitieren wir von aktiven Communities, die neue Funktionen entwickeln, Sicherheitslücken schnell schließen und Best Practices bereitstellen.
Ziel: Eine wiederverwendbare, modulare Plattform
Unsere Plattform sollte mehrere Anforderungen erfüllen: Sie musste skalierbar sein – etwa durch den Einsatz bewährter AWS-Dienste wie EKS, EC2, S3 und VPC. Gleichzeitig wollten wir alle Ressourcen per Infrastructure-as-Code verwalten, um Konsistenz und Reproduzierbarkeit zu gewährleisten. Auch das Deployment sollte vollständig automatisiert ablaufen – idealerweise über einen GitOps-Ansatz. Weitere wichtige Aspekte waren ein flexibler Aufbau, der sich an verschiedene Projektarten anpassen lässt, sowie eine zentrale Verwaltung von Nutzern, Secrets und Artefakten. Und natürlich: Monitoring und Observability mussten von Anfang an mitgedacht werden.
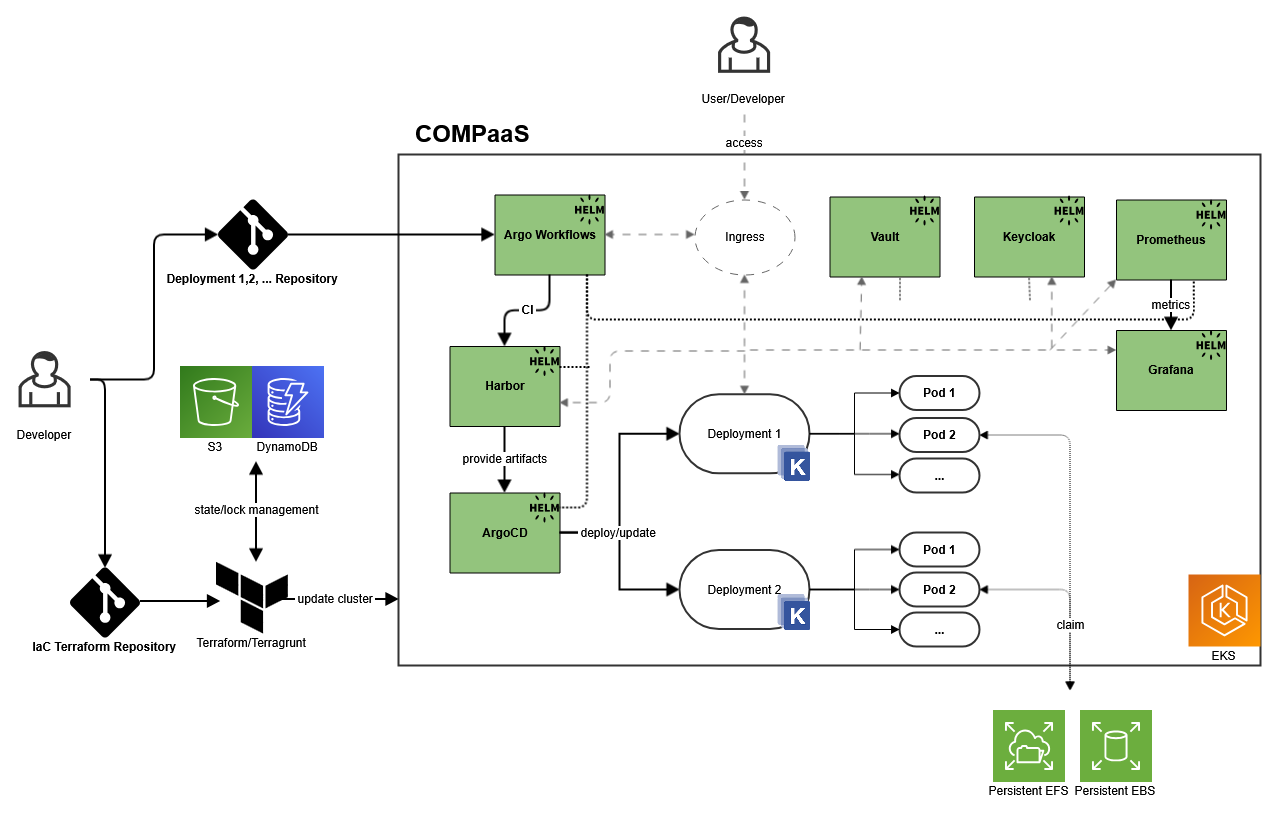
Unsere Architektur im Überblick
Technische Umsetzung
Die Plattform basiert auf mehreren Open-Source-Komponenten, die jeweils bestimmte Aufgaben übernehmen – von Infrastruktur über Authentifizierung bis Monitoring:
- Infrastruktur als Code mit Terraform & Terragrunt
Die komplette AWS-Infrastruktur wird mit Terraform beschrieben. Terragrunt hilft, Code für die verschiedenen Deployment-Umgebungen (z. B. dev, int, prod) strukturiert und wiederverwendbar zu gestalten. - GitOps mit Argo CD
Änderungen an Deployments erfolgen über Git. Argo CD synchronisiert Helm-Charts oder Kubernetes-Manifeste automatisch mit dem Cluster – zuverlässig und nachvollziehbar. - Argo Workflows für CI-Prozesse
Die Integration-Workflows (z. B. Testing, Linting, Docker-Builds) orchestrieren wir mit Argo Workflows – Kubernetes-nativ und erweiterbar für datenintensive Jobs. - Vault für Secret Management
Zugriffsdaten, Tokens oder Passwörter werden zentral über HashiCorp Vault verwaltet. Pods greifen sicher über Kubernetes-Auth auf ihre Secrets zu. - Keycloak für Identity Management
User, Rollen und Single Sign-on werden mit Keycloak verwaltet – auch über Projektgrenzen hinweg. Login-Integrationen erfolgen per OIDC oder SAML. - Harbor als Container-Registry
Container-Images und Helm-Charts hosten wir in einem eigenen Harbor-Repository – inklusive Schwachstellen-Scans und Rechtemanagement. - NGINX Ingress Controller
Für externen Zugriff auf Services sorgt NGINX Ingress – mit TLS-Verschlüsselung, Authentifizierung und Routing-Funktionalitäten. - Prometheus & Grafana für Monitoring
Prometheus erfasst Metriken zu Infrastruktur, Deployments und Workloads. Alerts helfen uns, auf Fehler frühzeitig zu reagieren. Grafana visualisiert diese Daten in übersichtlichen Dashboards – individuell pro Projekt und zentral für den gesamten Cluster.
Typische Anwendungsfälle
Unsere Plattform ermöglicht:
- Schnellen Projektstart ohne eigene Infrastruktur
- Multi-Tenant-Betrieb über Namespaces, RBAC und getrennte Pipelines
- Automatisiertes Deployment von Datenpipelines, Datenbanken, APIs, Web-Apps und jeder weiter Art von containerisierbarer Anwendung
- Machine-Learning-Workflows direkt im Cluster
- Zentrale Verwaltung von Zugriffen, Secrets und Images
- Transparente Überwachung von Anwendungen und Infrastruktur über Dashboards und Alerts
Beispiel: Internes AI-Ecosystem für Search und Assistenzfunktionen
Ein konkretes Beispiel ist ein internes Projekt, in dem wir ein AI-Ecosystem für Enterprise Search und intelligente Assistenzfunktionen entwickeln. Dabei setzen wir auf eine modulare Architektur mit Komponenten für Datenanbindung, Vektorsuche, Embedding-Generierung, Modell-Hosting und API-Zugriff. Unsere Plattform ermöglicht es uns, alle Bestandteile – von der Verarbeitung großer Textmengen bis hin zur KI-gestützten Antwortgenerierung – direkt im Cluster zu betreiben. Workflows laufen über Argo, Metriken und Logs fließen in Prometheus und Grafana, und Secrets sowie Zugriffskontrolle managen wir zentral über Vault und Keycloak.
Lessons Learned
Was hat sich für uns bewährt? Die Kombination aus Terraform und Terragrunt sorgt für Struktur und Klarheit, gerade bei mehreren Umgebungen. Unsere modulare Plattform reduziert den Aufwand für neue Projekte erheblich. Auch aus Kostensicht überzeugt der Ansatz: Die laufenden Ausgaben beschränken sich auf die Grundinfrastruktur – alle darüber liegenden Komponenten sind Open Source. Und: Frühzeitig integriertes Monitoring ist Gold wert – sei es fürs Debugging oder für die Kapazitätsplanung.
Fazit: Offen, flexibel, zukunftssicher
Mit unserer Plattform haben wir eine Lösung gefunden, die sowohl den Bedürfnissen unserer Entwicklerteams als auch den Anforderungen an Sicherheit, Skalierbarkeit und Monitoring gerecht wird.
Durch den modularen Aufbau und den Einsatz von Open-Source-Technologien bleiben wir unabhängig von Herstellern, vermeiden technologische Engpässe und können neue Projekte schnell und konsistent ausrollen – ohne jedes Mal bei null zu starten.
Automatisierte Prozesse, zentrale Verwaltung und integriertes Monitoring sorgen für einen stabilen Betrieb bei gleichzeitig hoher Anpassungsfähigkeit. So schaffen wir eine Infrastruktur, die mit unseren Anforderungen wächst – ob für datengetriebene Dienste, KI-basierte Workflows oder klassische Web-Anwendungen.
Zusammengefasst bedeutet das: weniger Betriebsaufwand, mehr Transparenz, geringere Abhängigkeiten – und eine Plattform, die heute schon auf die Herausforderungen von morgen vorbereitet ist.
Datenplattformen mit CONET
Steht auch Ihr Unternehmen vor wegweisenden Entscheidungen? Neue Technologien, wachsende Datenmengen und regulatorische Vorgaben verändern die Anforderungen an Datenplattformen grundlegend. Diese Entwicklungen sind herausfordernd, aber mit dem richtigen Partner an Ihrer Seite lösbar!
War dieser Artikel hilfreich für Sie? Oder haben Sie weiterführende Fragen zu Datenplattformen? Schreiben Sie uns einen Kommentar oder rufen Sie uns gerne an.
Über den Autor

Benedikt Klotz ist Student an der Technischen Universität München mit dem Schwerpunkt auf Machine Learning, Künstlicher Intelligenz und Data Science. Als Werkstudent bei der PROCON IT unterstützt er Projekte im Bereich moderner Datenarchitekturen und arbeitet an der Entwicklung und Optimierung von Data Pipelines in Cloud-basierten Umgebungen mit AWS und Kubernetes.




