

Machine Learning mit SAP PAL und Python
SAP hat die Version 1.0.5 ihrer „Python Client API for Machine Learning Algorithms“ (ML API) veröffentlicht. Ein Proof of Concept im HANA-Umfeld zum Thema „Anomalieerkennung in Zahlungsströmungen“ bot uns die Möglichkeit zum Test der ML API.

Learning ist nicht gleich Learning und kann zu mehr oder weniger zweckmäßen Ergebnissen führen.
Die Predictive Analysis Library (PAL)
Die PAL umfasst circa 90 in C++ geschriebene Algorithmen. Das Thema Machine Learning bildet den Schwerpunkt, aber auch neuronale Netze sind mit PAL möglich. Sollte die Bibliothek noch nicht installiert sein, so lässt sie sich bei Bedarf unkompliziert nachrüsten.
Die Doku von SAP umfasst je nach Versionsstand 700 bis 800 Seiten. Darin beschränkt sie sich aber im Wesentlichen auf eine knappe Beschreibung der Algorithmen beziehungsweise der benötigten Parameter sowie kurze Script-Beispiele (SAP SQL Script).
Eine SAP ML API for Python. Warum?
Bei den letzten Umfragen zum Thema populäre ML-Werkzeuge von KDNugget erscheint SAP HANA nur unter ferner liefen. SQL findet sich weit vorne. Der Darling ist jedoch Python. Der hohe Verbreitungsgrad, die umfangreichen Möglichkeiten sowie die schnelle Erlernbarkeit sind gute Gründe, Python auch bei SAP weiter zu integrieren.
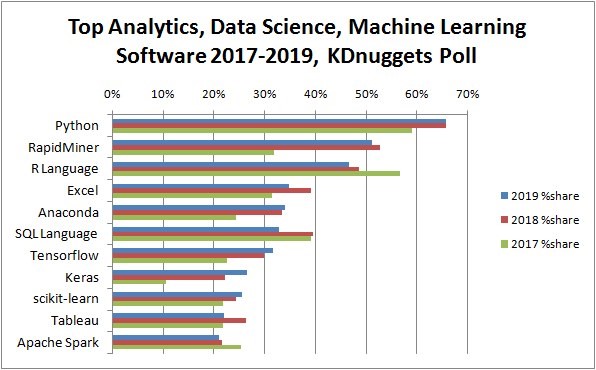
Die Top Tools für Analytics, Data Science und Machine Learning 2019 und ihre Anteile 2017 und 2018 (Quelle)
Was leistet die Programmierschnittstelle (API)?
In der aktuellen Version soll sie hauptsächlich eins leisten: Die PAL-Algorithmen aus Python heraus ansprechen. Zurzeit ist knapp die Hälfte der gelisteten PAL-Algorithmen für Python verfügbar, eine Komplettierung ist vorgesehen. Daneben werden verschiedene Methoden zur Datenmanipulation bereitgestellt. Explorative Tasks sind ebenfalls möglich – wie das Plotten von Diagrammen zum Beispiel mit Matplotlib (siehe unten).
Woher bekomme ich die API?
Das circa 120 KB umfassende Archiv wird zurzeit über den Download des Linux-Clients der HANA-Express-Version zur Verfügung gestellt. Die Installation erfolgt dann lokal mit pip. Die SAP ML API benötigt einen vorab installierten Python Connector (im SAP HANA Client enthalten). Dieser wiederum sollte laut SAP ein Python in der Version 3.4x vorfinden. Mittlerweile ist der Python-Connector auf PyPi gelistet und kann somit auch mittels pip install hdbcli installiert werden. Die durchaus hakelige, lokale Installation kann damit entfallen. Daneben werden für einen fehlerfreien Aufruf der PAL noch verschiedene AFL-Rollen benötigt.
Online-Dokumentation
Die Online-Doku gibt einen schnellen Überblick der verfügbaren Algorithmen, dem Verbindungsobjekt sowie den Möglichkeiten des HANA Dataframes. Die Doku patzt jedoch bei den Visualisierungsmöglichkeiten: Die Angaben hierzu fehlen trotz technischer Verfügbarkeit.
Vor der Veröffentlichung der nunmehr aktuellen Version 1.0.5 der API war die Vorgängerversion 1.0.3 monatelang aus dem Netz verschwunden. Eine lokale Version der Doku kann also ratsam sei.
Weitere Python-Module
Neben der Installation von Standardmodulen (zum Beispiel Pandas) kann die Installation von weiteren Modulen wie SQL Alchemy (der HANA-Dialekt benötigt eine zusätzliche Installation) und der Machine-Learning-Bibliothek Scikit-learn hilfreich sein. Heutzutage ein Muss: die Installation der Multifunktionsumgebung Jupyter und gegebenenfalls der Jupyter-Extensions (zum Beispiel zur Laufzeitmessung).
Testumgebung
Der Kunde wünschte einen technischen Proof of Concept (PoC) zum Einsatz von SAP HANA. Daneben erfolgte ein fachlicher PoC zur Anomalieerkennung in Zahlungsströmen. Technische Basis war ein BW on HANA. In das Szenario integriert, war das Produktiv-BW on anyDB (auf Basis eines MS SQL Server). Die benötigten Python-Module wurden Client-seitig installiert.
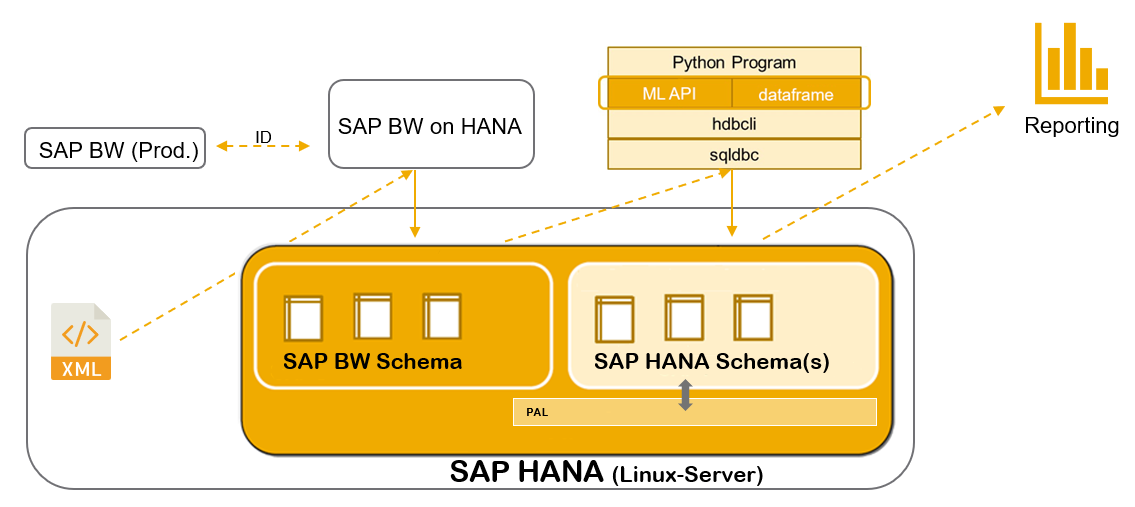
Das Zusammenspiel der PoC-Komponenten
Teststellung
Die Teststellung bestand darin, Auszahlungsdaten (Quelle: SEPA XML-Dateien) auf Anomalien zu untersuchen. Das Volumen der zu analysierenden Daten belief sich auf gut 120 Millionen Euro. Die technischen Begleitumstände (Parsen der XML-Dateien, Datenmodell etc.) sollen hier nicht weiter betrachtet werden.
Technische Umsetzung
Die XML-Dateien wurden auf dem Application Server des BW on HANA mittels ABAP eingelesen, die Ergebnisse in Z-Tabellen des SAP BW on HANA Schemas persistiert. Die Exploration und Transformation der Daten erfolgten mittels Python. Die bereinigten und harmonisierten Daten wurden in einem eigenen Schema persistiert und anschließend skaliert. Die skalierten Daten (ebenfalls auf der Datenbank gesichert) bildeten den Datenpool für die PAL-Algorithmen. Auch die PAL-Ergebnisse wurden persistiert und mittels Calculation Views einem Lumira-Dashboard zur Verfügung gestellt.
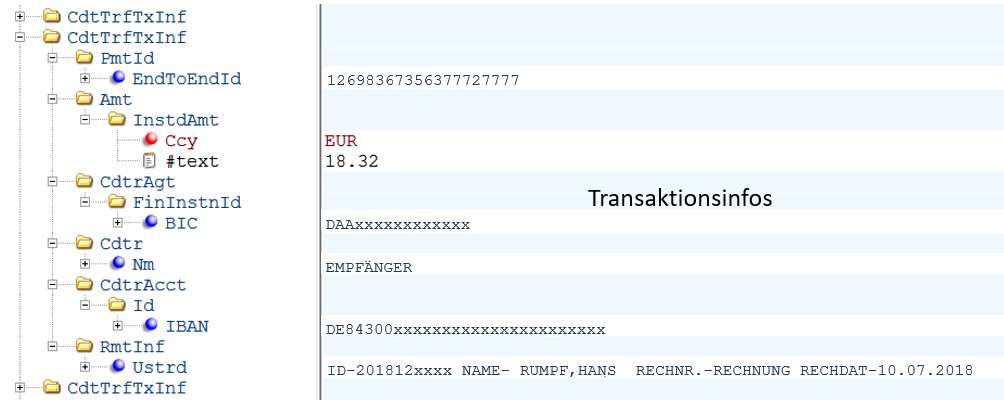
SEPA-XML-Datei, Auszug (Angaben geändert)
Ein Zugriff auf Daten des SAP ERP war nicht möglich. Gegen das Produktiv-BW prüfte unser Projekt-Team jedoch eine unternehmensinterne Vorgangs-ID auf ihre Richtigkeit. Bei dieser Gelegenheit übernahmen wir diese drei zusätzlichen Merkmale in die Anomalieerkennung:
- die geographisch zuständige Verwaltungseinheit zur Zahlung
- zwei Statushinweise zum fachlichen Ursprung der Zahlung
Merkmalsableitungen
Eine SEPA-Überweisung enthält, neben verschiedenen Begleitangaben (wie Einreichdatum und Prüfsummen), die eigentlichen Zahlungsangaben. Aus diesen konnten wir im vorliegenden Fall bereits verschiedene Merkmale ableiten. Der IBAN-Code enthält unter anderem einen Ländercode, die Bankleitzahl und die Kontonummer der Empfänger. So lassen sich zum Beispiel Zahlungen in das Ausland identifizieren. Der Verwendungszweck stellt ein kleines Füllhorn dar: Die unternehmenseigene Vorgangs-ID wurde hier ausgelesen sowie das Rechnungsdatum und diverse weitere Angaben (siehe unten).
Zu Testzwecken wurden verschiedene Merkmale erst in Python abgeleitet und nicht schon mittels ABAP in die Datenbank geschrieben. Beispielhafte Merkmale waren:
- eine virtuelle Debitoren-ID aus BLZ und Kontonummer
- die Bearbeitungszeit von Rechnungen
- Wochentage, an denen Rechnungen und Sammelüberweisungen (XML-Dateien) geschrieben wurden.
Ungelabelte Daten
Die bereitgestellten Daten waren ungelabelte Daten. Wenn eine Rechnung per SEPA zur Zahlung angewiesen wird, so sind sachliche und rechnerische Prüfungen bereits abgeschlossen. Deshalb hier der kurze Hinweis, dass es sich hier in erster Linie um Anomalieerkennung und nicht um Fraud-Detecting handelte.
Python und HANA – erster Kontakt
Der erste Python-Kontakt mit der HANA-DB (2.x) gestaltete sich recht problemlos, auch unterschiedliche Versionen der PAL-Bibliothek ließen sich ohne Schwierigkeiten ansprechen. Bei Bedarf kann der Klasse ConnectionContext auch ein Key des HANA Secure User Store übergeben werden. Damit sind insbesondere die Angaben zu Benutzer und Passwort geschützt.

Verbindungsangaben und ein einfaches SELECT
HANA Dataframe versus Pandas Dataframe
Der mit der ML API bereitgestellte HANA Dataframe erinnert mit seinen Methoden deutlich an die Möglichkeiten eines Pandas Dataframes. Der zentrale Unterschied liegt im SAP-Konzept des Dataframes. Die im Kontext eines HANA Dataframes durchgeführten Operation werden auf der Datenbank durchgeführt und liefern keine Daten zurück.
In der Doku weist SAP sehr deutlich darauf hin:
„This module represents a database query as a dataframe. Most operations are designed to not bring data back from the database unless explicitly asked for.“ (Quelle)
Das hat durchaus Konsequenzen: Möchte man die Daten in Augenschein nehmen, so müssen diese von der Datenbank abgerufen werden. Hier ist die Methode „Collect der API“ das Mittel der Wahl. Diese Methode überführt die bislang bearbeiteten Daten in einen Pandas Dataframe. Allerdings nun auch mit einem nicht vermeidbaren Nachteil: Die Daten werden zum Client transferiert. Das dauert. Der Transfer von 500.000 Datensätzen benötigt schon mal 50 bis 60 Sekunden. Im Vergleich: Eine gleichartige SQL-Abfrage braucht im HANA-Studio lediglich wenige Millisekunden.
Visualisierungskonzept
Das Visualisierungskonzept der ML API nutzt das Konzept des Code Pushdowns. Die für die Berechnung beispielsweise eines Histogramms nötigen Schritte werden an die HANA-Datenbank delegiert. Die Datenbank liefert nur die Werte zurück, die zur Darstellung des Histogramms nötig sind. Spannend – aus diesem Konzept kann sicher auch in Python noch mehr werden.
Python pur?
Natürlich ist es möglich, die Daten auch ohne die SAP ML API direkt in einen Pandas Frame zu übernehmen, zu bearbeiten und erst ganz zum Schluss der ML API zu übergeben. Zwar muss man auch hier anfangs die Performance-Kröte schlucken, doch dann steht die komplette Python-Welt zur Verfügung. Das kann in der Explorationsphase eines ML-Projekts interessante Vorteile mit sich bringen.
So sind dann zum Beispiel schnelle Pairplots mit Seaborn möglich. Oder der Einsatz des Label Encoders, eines Scalers aus Scikit-learn oder des Natural Language Toolkits (NLT). Im vorliegenden PoC wurde mit dem NLT der Verwendungszweck der Überweisungen analysiert, um weitere Merkmalsableitungen vorzunehmen.
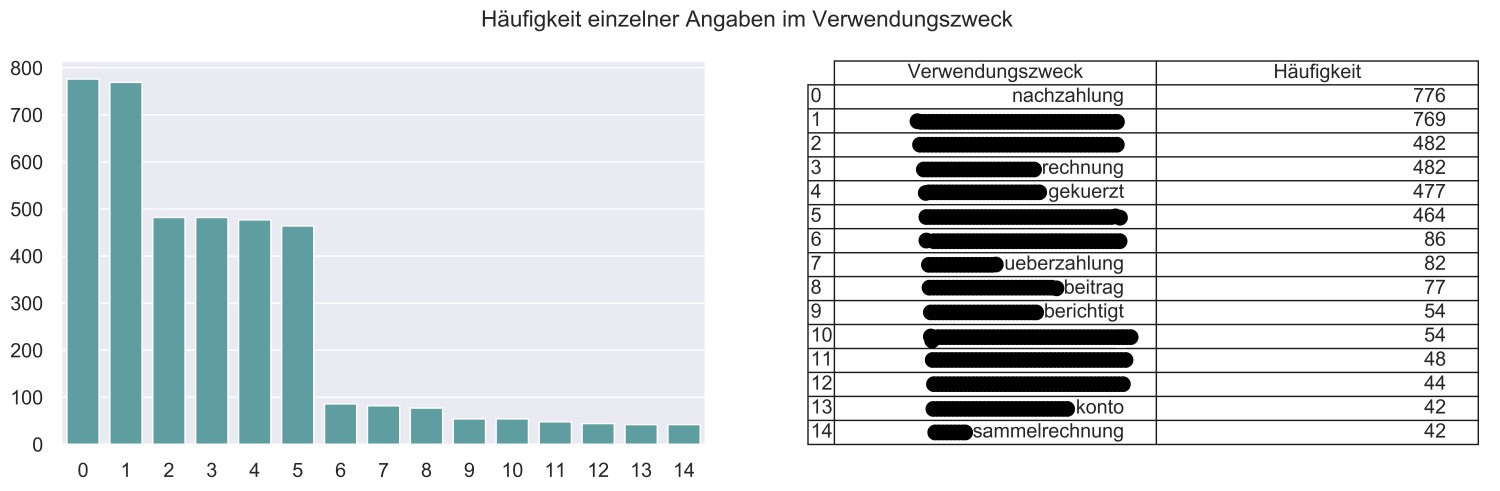
Natural Language Toolkit: Häufigkeit von Angaben im Verwendungszweck (in ausgewähltem Geschäftsbereich)
Clusterbildende PAL-Algorithmen
Wie bereits oben erwähnt, waren die Daten nicht gelabelt. Aus diesem und aus weiteren Gründen wurden Cluster-bildende Algorithmen eingesetzt. Hier beschreiben wir zwei:
PAL K-Means
Diverse Plots ließen uns bereits zweifeln, ob K-Means geeignet ist: Die Plots zeigten überwiegend eher nicht-konvexe Verteilungen der Daten. Begleitend wurden auch verschiedene Berechnungen in Python vorgenommen (zum Beispiel Elbow). Tests mit PAL K-Means waren zwar durchaus schnell und performant. Da aber unter anderem auch die Silhouettenwerte nicht überzeugten, nahmen wir PAL K-Means aus dem Rennen.
PAL DBSCAN
Der PAL DBSCAN kann die wichtigen Parameter MinPts und eps selbst ermitteln. Erste Tests auf dieser Basis waren schnell, performant und von überraschend guter Qualität. Nach einigen Tests und Anpassungen der Parameter fixierte das Team ein vorläufiges Zwischenergebnis. Die gebildeten Cluster überzeugten fachlich, hierzu zählt insbesondere auch der „Noise Cluster“. Dieser nimmt die Datensätze auf, die nicht mehr als dichteverbunden bewertet werden konnten.

Test-Parametrisierung DBSCAN
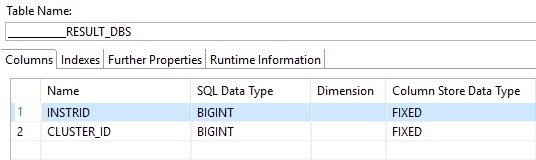
Typisierung der Ergebnistabelle des DBSCAN
Ergebnisanalyse I
Verschiedene Auswertungen zur Überprüfung der Ergebnisse führte CONET zum Teil in Python durch, zum Teil in SQL Script. Nachstehend ein Histogramm zur Verteilung der Rechnungsbeträge im Cluster 10. Der Durchschnittsbetrag über alle Beträge im PoC liegt knapp unter 500 Euro. Deshalb hier: Alles in Ordnung!
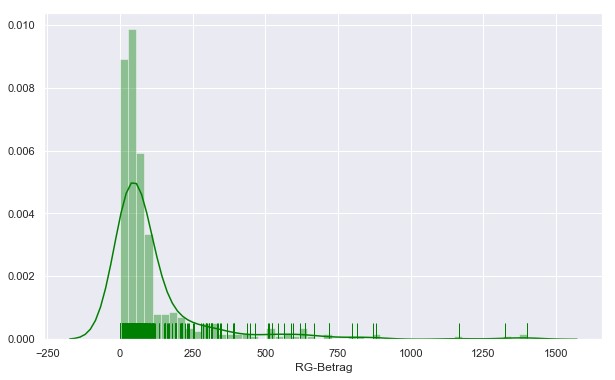
Cluster 10 – alles im grünen Bereich (Seaborn Distplot)
Ergebnisanalyse II – Auswertung mit Lumira
Den eigentlichen Nutzern der Ergebnisse stellten wir ein in Lumira entwickeltes Dashboard zur Verfügung. Dieses wurde auf Basis verschiedener Calculation Views mit Daten versorgt. Um Filter- und Suchmöglichkeiten ergänzte Diagramme und Tabellen ermöglichten schnelle Detailanalysen.
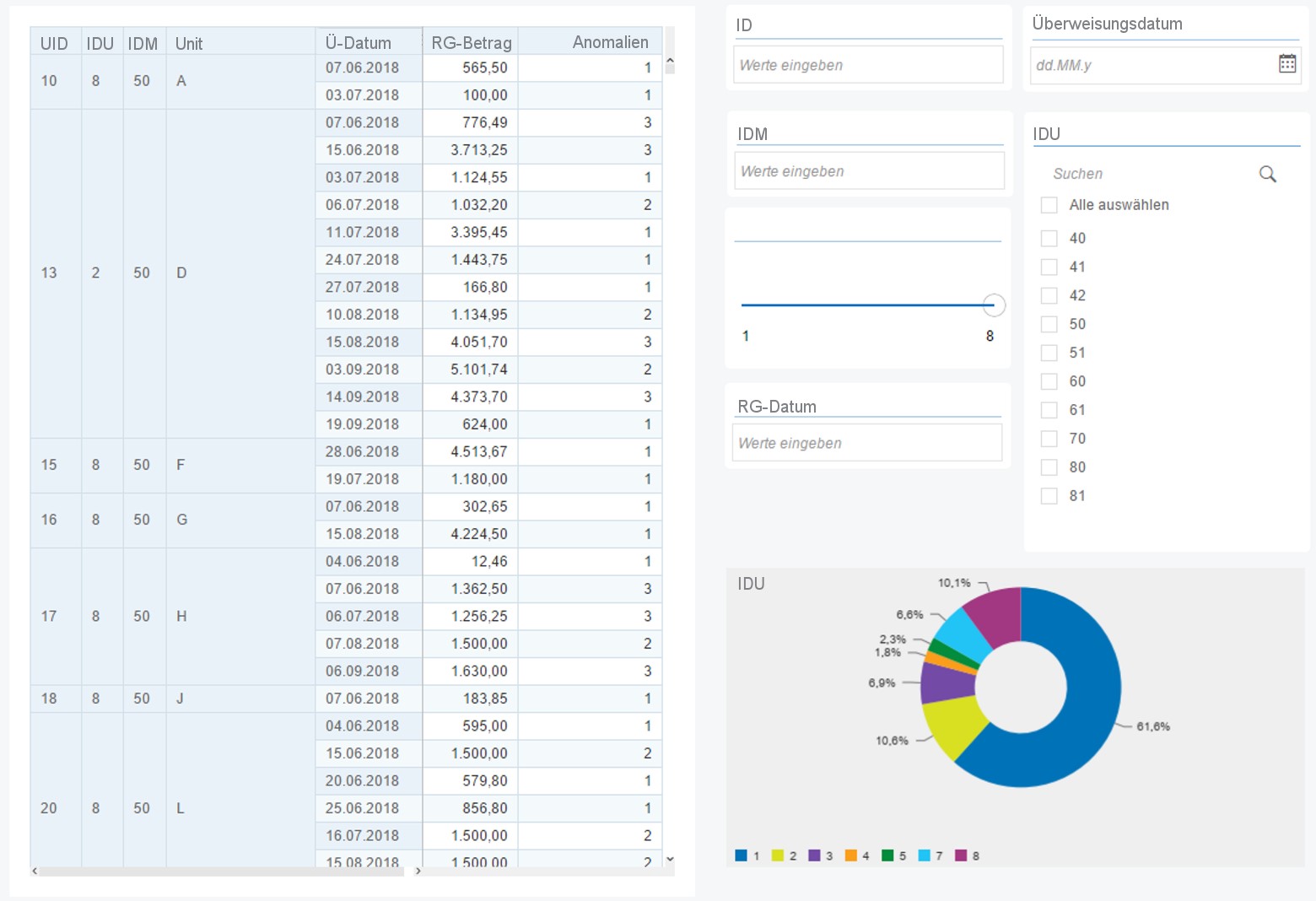
Lumira Dashboard: Tabellarische Übersicht mit Filtern und Suche (Ausschnitt)
Fazit: Das kann was werden
Eine schnelle und zuverlässige Ansprache der PAL-Algorithmen, ein interessantes Visualisierungskonzept für die Datenexploration, eine weitverbreitete Entwicklungsumgebung: PAL und die SAP ML API, ja, das kann was werden. Insgesamt ging die Arbeit flott von der Hand. Es hat Spaß gemacht. Und der Kunde war zufrieden.
Link-Tipps
- PyCon.DE 2018: Solving Data Science Probs With A Jupyter Notebook And SAP HANA’s Libs
- die SAP ML API auf Github
- Python Client API for machine learning algorithms
War dieser Artikel hilfreich für Sie? Oder haben Sie Fragen? Schreiben Sie uns einfach einen Kommentar oder rufen Sie uns gerne an.
Über den Autor
Marcus Pudwell ist SAP BW-Berater mit den Schwerpunkten ETL und Modellierung.




