
SAP HANA – Erfahrungen mit der In-Memory-Datenbank, Teil 1: Szenario und Datenerzeugung
Die SAP verspricht: „Mit SAP HANA lassen sich nicht nur Geschäftsprozesse beschleunigen, sondern auch vollkommen neuartige Anwendungen erzeugen.“
Hinter diesem Versprechen steht eine neue Datenbank-Technologie (In-Memory-Datenbank) mit möglicherweise weitreichenden Auswirkungen auf die zukünftige SAP-Landschaft.
In dieser Blog-Reihe wollen wir vorstellen, wie wir uns dem Thema HANA genähert haben. Unser Fokus lag hierbei zunächst auf der Entwicklung eigenständiger Anwendungen und hierbei insbesondere auf dem Schwerpunkt „Geschwindigkeit“.
Die nachfolgenden Ausführungen zu diesem Thema stellen unsere Ergebnisse mit HANA und einen Vergleich mit einer traditionellen SQL-Datenbank vor. Die Ergebnisse der SQL-Datenbank dienen hierbei als Referenz, um die HANA-Ergebnisse einordnen zu können. Durch Optimierung lassen sich die SQL-Ergebnisse sicherlich noch verbessern – dies steht aber nicht im Fokus unserer Untersuchungen.
Voraussetzungen
Für die Untersuchungen haben wir folgende Komponenten verwendet:
- einen Trial-Account auf der SAP HANA-Cloud-Plattform (https://account.hanatrial.ondemand.com)
- das SAP HANA Studio (https://hanadeveditionsapicl.hana.ondemand.com/hanadevedition/)
- das SAP HANA Cloud SDK (https://help.hana.ondemand.com/help/frameset.htm?7613843c711e1014839a8273b0e91070.html)
- die SAP HANA Cloud Tools (https://help.hana.ondemand.com/help/frameset.htm?76135112711e1014839a8273b0e91070.html)
Auf die Verwendung dieser Tools soll in diesem Blog nicht eingegangen werden. Hierfür steht im SAP Community Network eine hervorragende Startseite mit Links zu Dokumenten, Videos und weiteren Blogs zur Verfügung (http://scn.sap.com/community/developer-center/hana).
Szenario
Damit die Ergebnisse eine gewisse Aussagekraft erhalten, muss eine große Datenmenge für Datenbank-Operationen maschinell bereitgestellt werden.
Wir haben für unsere Untersuchung die deutschen Kfz-Kennzeichen als Grundlage verwendet.
Diese bestehen aus
- bis zu drei Buchstaben als Kennzeichen für den jeweiligen Landkreis
- bis zu zwei Buchstaben für die Unterteilung innerhalb des Landkreises und
- bis zu vier Ziffern für die weitere Unterteilung.
Damit lassen sich pro Landkreis 7.020.000 Kombinationen bilden. Durch die Integration weiterer Landkreise kann diese Anzahl praktisch beliebig erhöht werden.
Datengrundlage
Für unsere Untersuchungen haben wir eine möglichst einfache Datengrundlage in einer spaltenorientierten Datenbanktabelle verwendet.

Datenerzeugung
Das Befüllen der Tabelle muss natürlich automatisiert erfolgen. Hierzu haben wir verschiedene stored procedures in SAP HANA definiert.
Die stored procedure insert_kennzeichen_z4 ist der eigentliche „Lastesel“ mit den Insert-Statements.
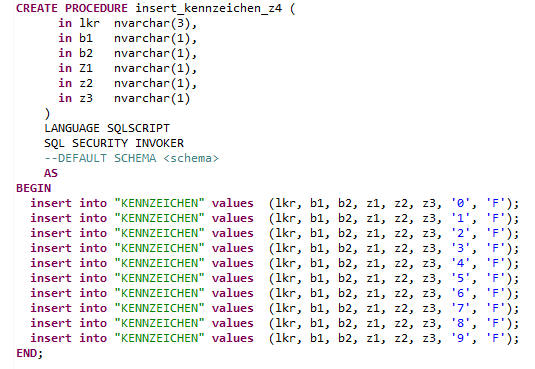
Diese Prozedur wird kaskadierend von den stored procedures insert_kennzeichen_z3, insert_kennzeichen_z2, insert_kennzeichen_z1 und insert_kennzeichen_b2 über jeweils unterschiedliche Übergabeparameter aufgerufen.

Die Generierung der Kennzeichen erfolgt zunächst über einen Aufruf der Prozedur insert_kennzeichen_b2. Über den folgenden Aufruf werden 270.000 Kennzeichen für den Landkreis AAA erzeugt, die alle als ersten Buchstaben ein ‚A‘ haben.
![]()
Die Ausführung dieser Anweisung in der SQL Console des SAP HANA Studios (mit Zugriff auf die SAP HANA Cloud über einen DB-Tunnel) dauert 3:28 Minuten.
Mmh – das ist jetzt nicht besonders schnell. Wenn wir das für alle möglichen 26 Buchstaben hochrechnen, die als erster Buchstabe in das KFZ-Kennzeichen eingesetzt werden können, kommen wir auf eine Dauer von etwa 90 Minuten.
Das führt uns zu einer anderen Vorgehensweise: für die Buchstaben B bis Z an der ersten Stelle des KFZ-Kennzeichens verwenden wir die Anweisung

Und siehe da: diese Anweisung benötigt weniger als 40 ms !! Hier sehen wir eine erste Auswirkung des schnellen In-Memory-Datenzugriffs. Hiermit schaffen wir die restlichen 25 Buchstaben in etwa einer Sekunde (!!) und haben somit die 7.020.000 Datensätze in etwa 3,5 Minuten erzeugt. Nicht schlecht – oder? (Natürlich ließe sich auch der erste Schritt noch optimieren, so dass der gesamte Vorgang sogar in weniger als 1 Minute zu schaffen wäre).
Alle neu erzeugten und alle geänderten Datensätze werden in SAP HANA in einem so genannten Delta-Buffer abgespeichert. Dieser Delta-Buffer wird regelmäßig in den Standard-Datenbereich überführt. Mit der Angabe „AUTO MERGE“ bei der Definition der Tabelle erfolgt dies automatisch.
Wir wollen die hierfür notwendige Zeit aber in unsere Betrachtungen mit einfließen lassen. Zum Abschluss wird deshalb der erzeugte Delta-Buffer noch manuell in den Standard-Datenbereich überführt:
![]()
Dieser Vorgang dauert für alle neu erzeugten Datensätze weniger als 400 ms und ist somit für die Gesamtdauer vernachlässigbar.
Vergleich zu SQL
Das oben beschriebene Vorgehen haben wir analog mit einer traditionellen SQL-Datenbank durchgeführt.
Dabei wurden folgende Werte ermittelt:
| Statement | Dauer SQL-Datenbank | Dauer HANA |
| CALL INSERT_KENNZEICHEN_B2 | 1:30 Minuten | 3:28 Minuten |
| insert into … select from | 1:30 Minuten | 40 ms |
Für die Gesamtdauer der Erzeugung der 7.020.000 Datensätze ergeben sich folgende Kennzahlen:
SQL-Datenbank ca. 40 Minuten
HANA ca. 3,5 Minuten
Fazit Teil 1
Wir haben in diesem ersten Teil gesehen, dass SAP HANA bereits bei Insert-Operationen einen deutlichen Geschwindigkeitsvorteil gegenüber einer traditionellen SQL-Datenbank besitzen kann. Bereits hier können wir vermuten, dass dies an einem extrem schnellen Lesevorgang im Rahmen einer INSERT-INTO- … SELECT FROM – Anweisung liegt.
Allerdings ist auch zu beachten, dass HANA bei reinen INSERT-Operationen langsamer ist als eine traditionelle Datenbank. Diese Tatsache entspricht zwar durchaus den von HANA bekannten Randbedingungen, muss aber für konkrete Anwendungssituationen berücksichtigt werden.
Im zweiten Teil werden wir gezielt auf die Performance von SELECT- und UPDATE-Operationen eingehen.
Über den Autor

Rolf Gadorosi leitet bei der CONET Business Consultants GmbH die Business Unit SAP NetWeaver Development & Administration. In dieser Funktion fungiert er auch als organisatorischer und technischer Projektleiter und System Architect im Schwerpunkt mit Konzeption, Analyse, Design, Realisierung und Einführung von Individuallösungen und Erweiterungen auf Basis der SAP-Produktpalette.




